Understanding Cache Modules
The Data Hierarchy
Here is a fancy diagram ripped from my class lecture notes explaining the role of cpu cache and its relation to other storage devices.(credits to Travis Mcgaha and Bryant and O'Hallaron).
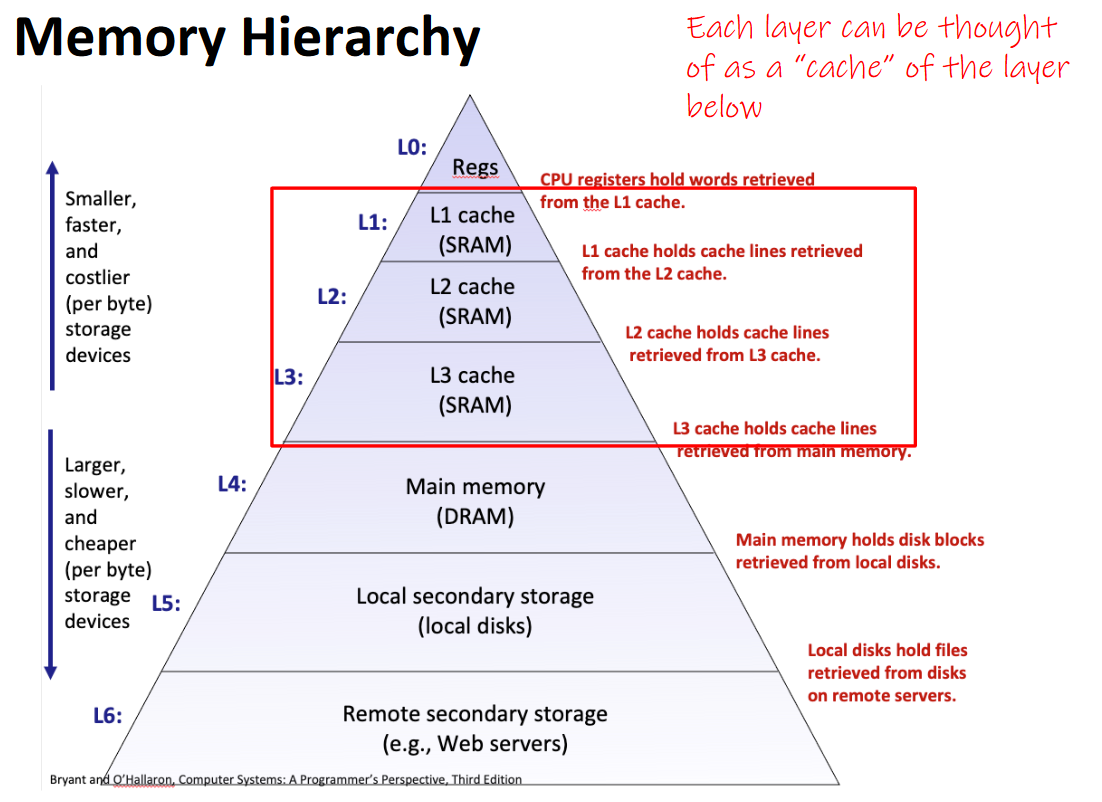
The cache (or SRAM) in your system has normally 3 levels, L1, L2, and L3. The cache is directly built on the CPU module, leading to extremely fast accesses and is a large reason for the speed of modern programs.
The cache stores data that has been fetched from your DRAM (system memory) and holds it until the cache is filled. This applies to both data and instructions that are pulled from memory, leading to the separate data and instruction caches both having separate, but similarly powerful effects on performance.
When the same instruction or data reference is accessed multiple times in a row, we take advantage of temporal locality, which means the data is unlikely to have left cache by the time it is referenced again.
Spatial locality is based off the principle that a reference in memory is likely to be accessed along with its neighbors (think iterating through an array). Thus, the cache prefetches 64 bytes (1 cache line), along with any reference that was pulled from DRAM. This causes data that is small and spaced close to take advantage of cache easily as more data points can be prefetched at once.
Having to go out to DRAM is called a cache-miss, and it has huge ramifications for performance versus programs that can effectively take advantage of cache. To demonstrate, let's look at the classic example for how big a difference cache makes.
Array-Lists to Linked-Lists.
Isn't insertion faster on a linked list than on an array list? Isn't deletion? Only if you're looking at algorithmic complexity.Let's run the following C++ bench comparing std::vector to std::queue in operations that queue should be doing better in.
//instantiate empty vector and list
std::vector sorted_vec;
std::list sorted_list;
for (int i = 0; i < TEST_SIZE; i++) {
//generate a random number in a large range we set with udist.
int rand_num = (int) udist(rng);
//we insert into the proper spot to keep the vector sorted
sorted_vec.insert_sorted(rand_num);
}
for (int i = 0; i < TEST_SIZE; i++) {
//generate a random number in a large range we set with udist.
int rand_num = (int) udist(rng);
//we insert into the proper spot to keep the list sorted
sorted_list.insert_sorted(rand_num);
}
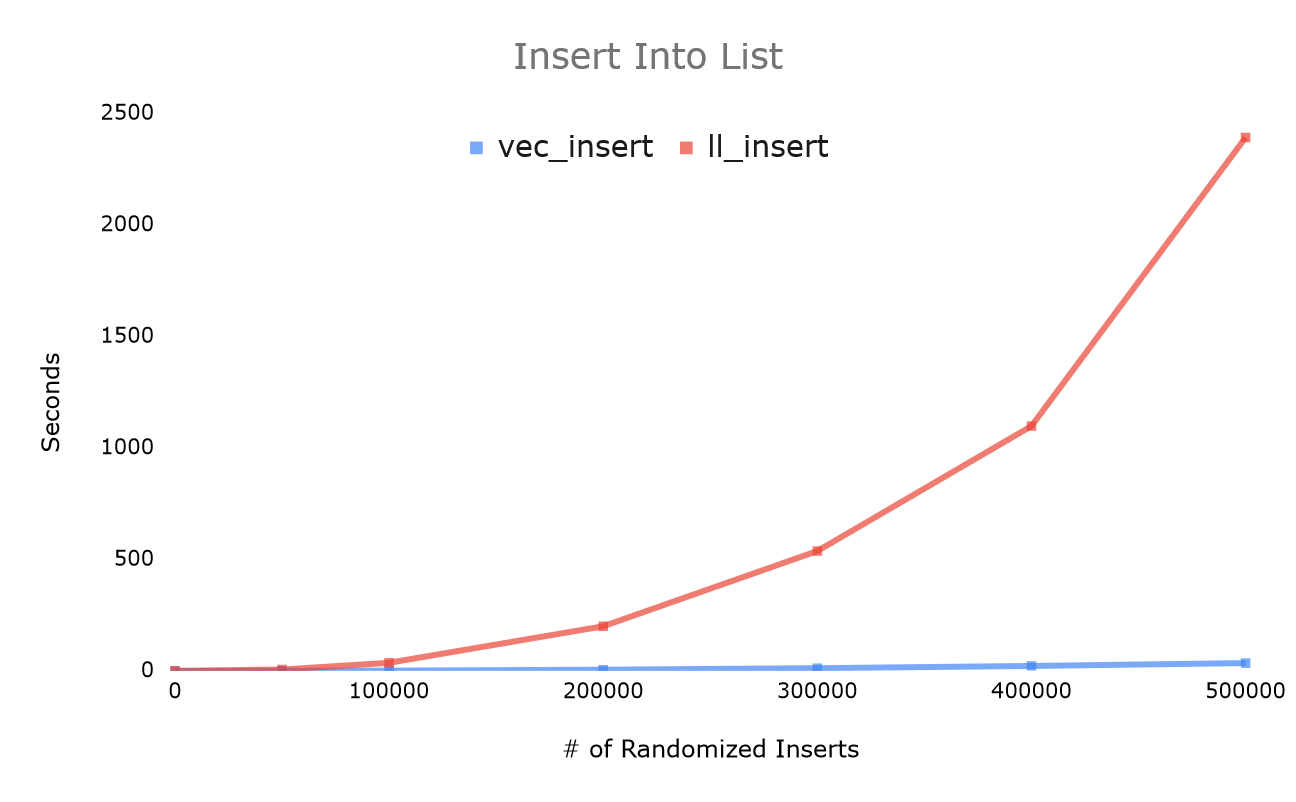
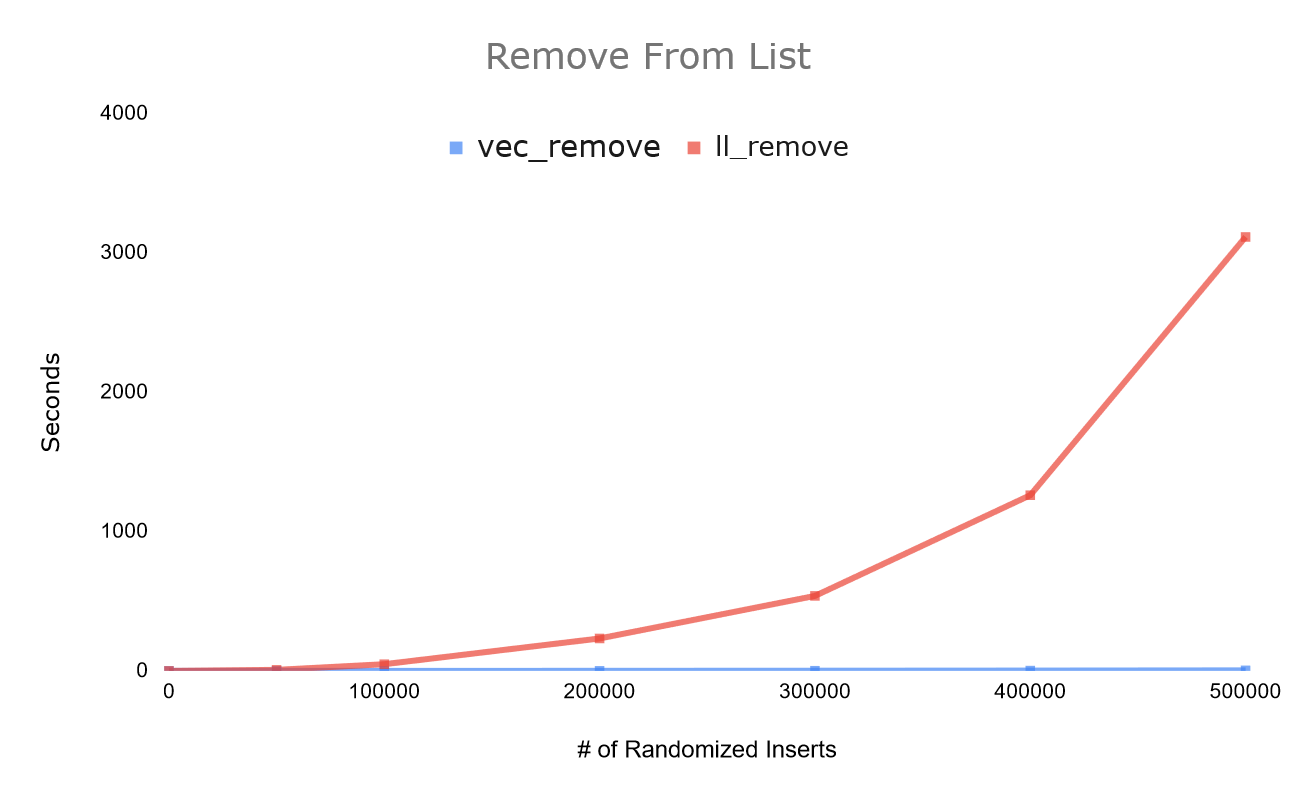
Seeing this demonstration for the first time definitely opened my eyes to new types of optimization.
As a quick analysis, the vector operations run hundreds of times faster, and scale better with volume than the list operation as well. If you're coming from my deque post, it's quite obvious why it's important to make sure your calls to malloc help the deque take advantage of cache, but unfortunately no pointer-based list can compare to the array list. This is why C++'s deque implementation actually relies on using an internal array like a vector, and allows resizing on both ends as an alternative to allocating each node individually.
This demonstration gives another reason to believe in benchmarking code, CPU's and algorithms don't run at asymptotic speeds, nor is the data structure choice the end all be all, it's just about how fast it runs.